Real Time Speech to Text With Whisper
Some friends and I were curious whether we could believably mimic a human phone caller using LLMs. We imagined a system where users can dial in, speak to a computer, and have an experience that feels truly human. Aside from generating sensible responses, the system would need to keep a conversational cadence, avoiding awkward pauses.
We thought we may be able to produce reasonable output quickly enough by building prompts while the human caller spoke, then pre-fetching potential responses from an LLM. So, we started to focus on how immediately we could make an audio stream available as text.
None of us had real-world audio or natural language processing experience, but OpenAI had just released a speech recognition model called Whisper, which we used to hack together a real-time Speech-to-Text prototype. The prototype streams in audio from a microphone and uses the method described below to convert it into a tokenized stream of text. The resulting transcription is often far from perfect, but it has proven to be good enough for an LLM to understand:
An example transcription from reading a paragraph of the Chess Wikipedia page
Here’s some code for those who prefer to explore at their own pace. There is still much room for improvement, especially around handling pauses in speech, but the bones are there. Contributions are welcome!
How It Works
Whisper converts audio files containing speech into a textual representation, but there is no real-time streaming API. For good results, context matters - Whisper can more accurately transcribe a full sentence than a single word. Therefore, our challenge was to convert an audio stream into a text stream, minimizing latency, using a tool that is fundamentally a batch file processor. Accuracy could be sacrificed to reduce lag, as long as the backend LLM was given sufficient information to generate a quality response.
The system we built buffers W sliding windows of audio input, each with a fixed duration, D. Each window is offset from the previous window by some step interval, S, and transcribed to text by Whisper, like this:
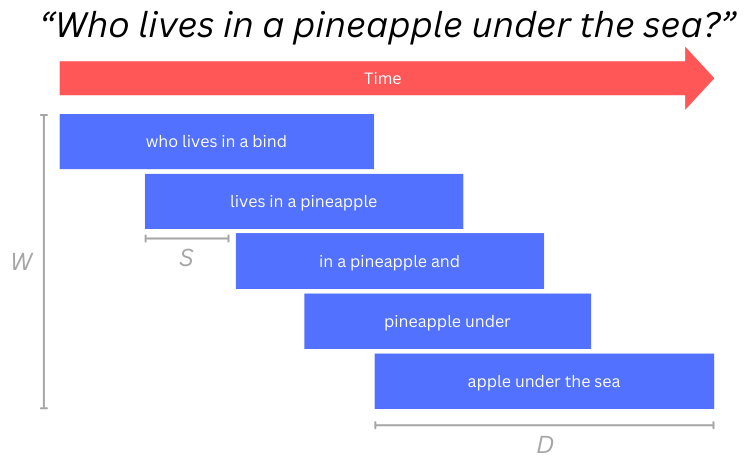
When a new window is buffered, the oldest buffered window is forgotten. Notice that, because each window might begin or end in the middle of a word, transcriptions near window boundaries tend to be less accurate, and transcriptions of words or phrases might be inconsistent over time. To overcome this, given a sequence of W windows, we can use simple probability to predict what the speaker is saying. For example, if we’ve just emitted “in a” and 2 out of 3 previous windows agree that the next word is “pineapple”, then we know the next word is probably pineapple.
W, D, and S can be adjusted to trade off quality, latency, and efficiency. Increasing window duration can result in more accurate transcriptions and better predictions, but will increase the initial wait and inference time. Decreasing the step interval can lower latency, but will run Whisper inference more often and may require a longer window buffer to be kept.
Depending on the inference capabilities of the host machine, larger Whisper models can be used to produce better results. However, if inference runs too slowly to keep up with the step interval, the system will start lagging farther and farther behind and eventually run out of space in its internal buffers.
Implementation
That’s it for the high-level overview! If you’re interested in implementing something similar yourself, better understanding the code linked above, or simply enjoy getting into the weeds, this section is for you.
Windows as Markov Chains
In practice, instead of storing raw audio or transcribed text for each window in the buffer, we store a Markov chain. When a new window is received, it is transcribed, tokenized, and passed to each Markov chain for training so that the oldest buffered Markov chain has always been trained on the last W windows. Each Markov chain uses an n-gram length of N to construct its frequency table, and a history is kept of the last N emitted tokens. Producing the next token is a matter of asking the oldest buffered Markov chain to predict the next token, given N recently emitted tokens.
NOTE: Since we always want the most likely next token instead of sampling a probability distribution, a small hack to the Markov chain library, gomarkov, was needed.
Output Rate
Choosing the rate at which tokens are emitted is crucial for good results, but tricky, especially considering that speech patterns can vary from person to person. If tokens are emitted too slowly, the system falls behind and loses context; if they are emitted too quickly, bad tokens resulting from truncated words at the end of each window will ruin the output.
After every step interval, the number of tokens to emit is determined by predicting the relative position of the previous N emitted tokens within the current window. This is crudely (but effectively) implemented as a linear search using edit distance as a qualifier. Tokens are emitted until the estimated position reaches a threshold within the current window. This strategy is a best-effort attempt at keeping up with the input rate, but ignoring tokens that may originate from truncated words.
NOTE: Using edit distance to predict the relative position assumes that words that sound similar also have similar spellings. In practice, this works well enough for English, but it has not been tested with other languages. Instead, if there was a way to map tokens back to their position in the original audio stream, the search would be unnecessary, which would be a big improvement in both efficiency and quality of the output.
Recovering From Inaccuracies
Ideally, the correct token is always emitted, but inaccuracies are inevitable because of bad audio quality, unclear speech, or inconsistent results from Whisper. When this situation arises, the oldest buffered Markov chain doesn’t know how to predict the next token, and we get stuck.
To recover, we use the same relative position estimate described above to find the most likely place to pick back up again. The emitted token history is rewritten using the current window as ground truth, and we start producing tokens once again from that point forward.